 The 18th International World Wide Web Conference, www2009 finished last week in Madrid. In times of global economic, pandemic and ecologic crisis, the value of attending international conferences is questionable, so for armchair delegates like me, here are some www papers and www links that are www worth a look. Obviously, virtual conference attendance via the Web is no substitute for The Real Thing® in Real Time with Real People® , but it is cheaper and has a considerably smaller Carbon footprint than actual conference attendance. So, in no particular order, some www interesting www stuff: (more…)
The 18th International World Wide Web Conference, www2009 finished last week in Madrid. In times of global economic, pandemic and ecologic crisis, the value of attending international conferences is questionable, so for armchair delegates like me, here are some www papers and www links that are www worth a look. Obviously, virtual conference attendance via the Web is no substitute for The Real Thing® in Real Time with Real People® , but it is cheaper and has a considerably smaller Carbon footprint than actual conference attendance. So, in no particular order, some www interesting www stuff: (more…)
May 1, 2009
www2009: Twentieth Web Anniversary
April 25, 2008
WWW2008: The Great Firewall of China
![Passage [The Great Wall / Beijing] by d'n'c](https://i0.wp.com/farm1.static.flickr.com/39/109209278_3415a788ef_m.jpg) The seventeenth international World Wide Web conference (WWW2008.org) is currently finishing in Beijing, China. There are some interesting papers this year. Thankfully, the Great Firewall of China doesn’t prevent these papers reaching the rest of the world. It’s One World, One Web (allegedly). Here are some brief highlights from the conference. (more…)
The seventeenth international World Wide Web conference (WWW2008.org) is currently finishing in Beijing, China. There are some interesting papers this year. Thankfully, the Great Firewall of China doesn’t prevent these papers reaching the rest of the world. It’s One World, One Web (allegedly). Here are some brief highlights from the conference. (more…)
September 5, 2007
WWW2007: Workflows on the Web
 The Hitch-hiking novelist Douglas Noel Adams (DNA) once remarked that the World Wide Web (WWW) is the only thing whose shortened form – ‘double-you double-you double-you-dot’ – takes three times longer to say than what it’s “short” for [1]. If he were still with us today, there is plenty of stuff at the 16th International World Wide Web conference (WWW2007), currently underway in Banff, that would interest him. Here are some short, abbreviated notes on a couple of interesting papers at this years conference. They are relevant to bioinformatics and worth reading, whichever type of DNA you’re most interested in.
The Hitch-hiking novelist Douglas Noel Adams (DNA) once remarked that the World Wide Web (WWW) is the only thing whose shortened form – ‘double-you double-you double-you-dot’ – takes three times longer to say than what it’s “short” for [1]. If he were still with us today, there is plenty of stuff at the 16th International World Wide Web conference (WWW2007), currently underway in Banff, that would interest him. Here are some short, abbreviated notes on a couple of interesting papers at this years conference. They are relevant to bioinformatics and worth reading, whichever type of DNA you’re most interested in.
One full paper [2] by Daniel Goodman describes a scientific workflow language called Martlet. The motivating example is taken from climateprediction.net but I suspect some of the points they make about scientific workflows are relevant to bioinformatics too. Just like the recent post by Boscoh about functional programming, the paper discusses an inspired-by-Haskell functional approach to building and running workflows. Comparisons with other workflow systems like Taverna / SCUFL are drawn. Despite what they say, Taverna already uses a functional model (not an imperative one), it just hasn’t been published yet. The paper also draws comparisons between Martlet and other functional systems, like Google’s Map-Reduce. It concludes that the (allegedly) new Martlet programming model “raises the interesting possibility of a whole set of new algorithms just waiting to be discovered once people start to think about programming in this new way”. Which is an exciting possibility.
Another position paper [3] (warning: position paper = arm waving) by Anupriya Ankolekar et al argues that the Semantic Web and Web-Two-Point-Oh are complementary, rather than competing. Their motivating examples are a bit lame (Blogging a movie? Can’t they think of something more original?) …but they make some interesting (and obvious) points. The authors think that aggregators like Yahoo! Pipes! will play an important role in the emerging Semantic Web. Currently, there don’t seem to be too many bioinformaticians using Yahoo! pipes, perhaps they just don’t share their pipes / workflows yet?
Running in parallel to all of the above is the Health Care and Life Sciences Data Integration for the Semantic Web workshop, where more detailed discussion on the bio semweb is underway. As its a workshop, there are no full or position papers, but take a look at The State of the Nation in Life Science Data integration to get a flavour of what is going on.
Wether functional, semantic, Web-enabled or just buzzword-friendly, there is plenty of action in the scientific workflow field right now. If you’re interested in the webby stuff, next years conference, WWW2008, is in Beijing, China. I wonder if they will mark the 10th anniversary of the publication of that Google paper at WWW7 back in 1998? The deadline for papers at WWW2008 will probably be sometime in November 2007, but around 90% of submitted papers will be rejected if previous years are anything to go by. If you’re thinking of doing a paper, DON’T PANIC about those intimidating statistics, because bioinformatics is bursting full of interesting and hard problems that challenge the state-of-the-art. The kind of stuff that will go down well at Dubya Dubya Dubya.
(Photo credit: Fire Monkey Fish)
References
- Douglas Adams (1999) Beyond the Brochure: Build it and we will come
- Daniel Goodman (2007) Introduction and Evaluation of Marlet, a Scientific Workflow Language for Abstracted Parallelisation doi:10.1145/1242572.1242705
- Anupriya Ankolekar, Markus Krotzsch, Thanh Tran and Denny Vrandecic (2007) The Two Cultures: Mashing up Web 2.0 and the Semantic Web doi:10.1145/1242572.1242684

This work is licensed under a
Creative Commons Attribution-Noncommercial-Share Alike 3.0 License.
May 24, 2006
Dub Dub Dub 2006

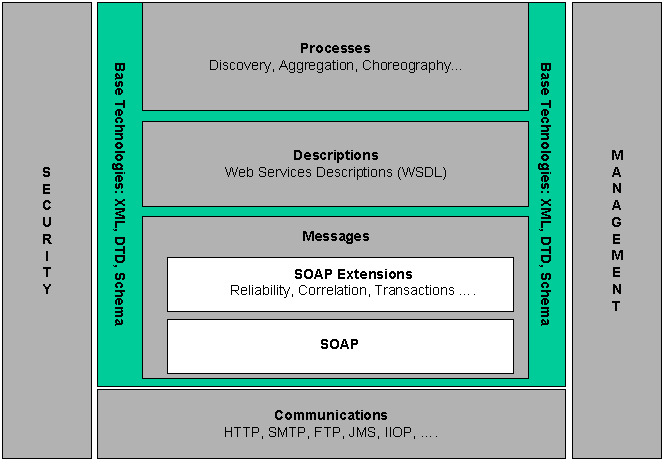
The 15th International World Wide Web conference is currently underway in Edinburgh, Bonny Scotland. As usual, this popular conference has some good papers, only 11%* of submissions are accepted. One particular paper caught my eye: One Document to Bind Them: Combining XML, Web Services, and the Semantic Web. This paper has probably been selected because it will wind people up (sorry I mean “spark a debate”) so its an entertaining and sometimes enlightening read.
In this paper, Harry Halpin and Henry Thompson make some observations about the state of the web in 2006:
- The Semantic Web stack and Web Service Stack, are a long long way from the web of everyday users, or to put it another way, there is too much theory and not enough practice.
- The web is in danger of becoming fragmented between XML, Web Services, Semantic Web, Second generation web, Asynchronous JavaScript and XML (AJAX) and microformats like Really Simple Syndication (RSS) etc
But, according to the authors, it doesn’t have to be this way…
- Many (but not all) web services are functions that are available on the web,
- The semantic web gives us an elaborate type system, using ontologies, which can extend what we already have with XML Schema
- The combination of the first two, gives us Semantic Web Services which are typed functions. This allows us to invoke web services not just by their URI (e.g. http://xml.nig.ac.jp/xddbj/Blast for a Blast service), but by the type of information they have. E.g. you have an output of type BLAST_report or perhaps InterProScan_report, what services will take this as input? What operations can be performed on this data? This sounds a lot like BioMOBY, with bells on.
What Harry and Henry propose is tying all this together using a single XML vocabulary, called Semantic fXML, to put “a unified abstraction of data, types and functions” so that the web can compute. This is all a bit pie-in-the-sky vision of the future stuff, but what might it mean for your average bioinformatican? It would be seriously useful if we could make the current molecular biology web services easier to use, but agreeing on and using an ontology for annotating the types of the inputs and outputs of all the services is non-trivial task. Bioinformaticians already have a (somewhat limited) universal type system for describing all data in bioinformatics, its called string. Persuading them to use something more powerful is not easy unless the benefits are immediately obvious.
At the moment, it is difficult to tell if sfXML will ever have any impact on bioinformatics but who cares? Despite this, the paper is enjoyable reminder of what is interesting about services on the Web. They transform the web from a place where we can merely search and browse for data (sequences, genes, proteins, metabolic pathways, systems etc), into “one vast de-centralised computer” a bit like the one described in can computers explain biology? This, in my humble opinion, is what makes the web and bioinformatics an exciting place to work in 2006.
* Footnote: Of nearly 700 papers submitted: only 81 research papers were accepted (11%). This is a 25% increase on the number of submissions last year to www2005 in Chiba, Japan.
References
- Harry Halpin and Henry S. Thompson (2006) One Document to Bind Them: Combining XML, Web Services, and the Semantic Web in Proceedings of the 15th international conference on World Wide Web, Edinburgh Scotland DOI:10.1145/1135777.1135877
- This post originally published on nodalpoint with comments

{kind=link}