![Passage [The Great Wall / Beijing] by d'n'c](https://i0.wp.com/farm1.static.flickr.com/39/109209278_3415a788ef_m.jpg) The seventeenth international World Wide Web conference (WWW2008.org) is currently finishing in Beijing, China. There are some interesting papers this year. Thankfully, the Great Firewall of China doesn’t prevent these papers reaching the rest of the world. It’s One World, One Web (allegedly). Here are some brief highlights from the conference. (more…)
The seventeenth international World Wide Web conference (WWW2008.org) is currently finishing in Beijing, China. There are some interesting papers this year. Thankfully, the Great Firewall of China doesn’t prevent these papers reaching the rest of the world. It’s One World, One Web (allegedly). Here are some brief highlights from the conference. (more…)
April 25, 2008
WWW2008: The Great Firewall of China
July 21, 2006
AAAI: Dude, Where’s My Service?
 As the number of bioinformatics services on the web increases, finding a tool or database that performs the task you require can be problematic. At the AAAI poster session on Wednesday, I presented our paper describing a novel solution to this problem. It uses a reasoner to “intelligently” search for web services, by semantically matching service requests with advertisements and has some advantages over comparable solutions…
As the number of bioinformatics services on the web increases, finding a tool or database that performs the task you require can be problematic. At the AAAI poster session on Wednesday, I presented our paper describing a novel solution to this problem. It uses a reasoner to “intelligently” search for web services, by semantically matching service requests with advertisements and has some advantages over comparable solutions…
I won’t go into all the gory details here but our technique extends and complements current approaches for matchmaking services. Some of the key features described in the paper are that it allows you describe to relationship(s) between the input and output of a service. E.g. What is the relationship between the input and output protein sequence of InterProScan? This relationship can help match requests for services with their adverts with higher precision and recall. I don’t mind admitting its been hard work getting this research published because a large part of the AI community use shamelessly toy and fictitious scenarios to motivate their work. Then they build incredibly complicated software stacks that are only understood by the small clique of people that designed them. When you show some of these people real-world bioinformatics services, they don’t seem to care too much, preferring to bury their heads in the sand of make-believe. There, thats got it off my chest!
So it was re-assuring when people came by the poster, listened to my speel and asked lots of questions. Ora Lassila from Nokia (one of the people responsible for hyping the whole idea up in the first place) dropped by to have a look. He was interested in adapting the technique for locating services in a registry, used by mobile devices. (I wonder if anyone out there needs BLAST on their mobile phone?!) It was good to meet Ora, and talk about semantics.
There is nothing quite like standing in front of a poster for three hours and tirelessly explaining it to complete strangers who work in disparate fields. It certainly helps to get your ideas straight. Where would we be without conferences?
References
- Danny Leiner (2000) Dude, Where’s My Car?
- Massimo Paolucci, Takahiro Kawamura, Terry Payne and Katia Sycara (2002) Semantic Matching of Web Service Capabilities
- Duncan Hull, Evgeny Zolin, Andrey Bovykin, Ian Horrocks, Ulrike Sattler and Robert Stevens (2006) Deciding Semantic Matching of Stateless Services in the Proceedings of the Twenty-First National Conference on Artificial Intelligence (AAAI-06)
June 2, 2006
Debugging Web Services
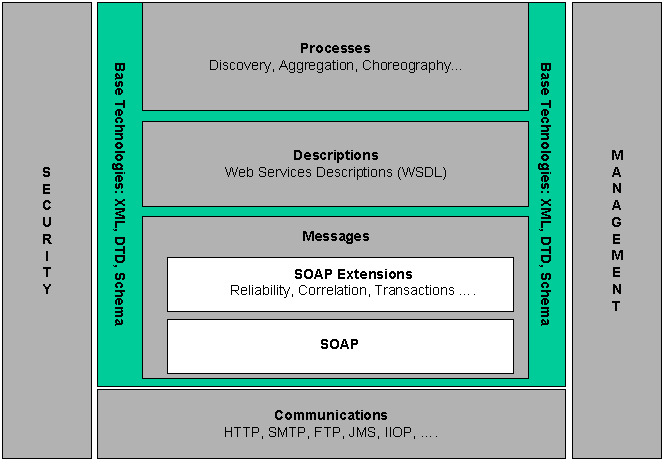
 There are a growing number of biomedical services out there on Wild Wild Web for performing various computations on DNA, RNA and proteins as well as the associated scientific literature. Currently, using and debugging these services can be hard work. SOAP UI (SOAP User Interface) is newish and handy free tool to help debug services and get your in silico experiments and analyses done, hopefully more easily.
There are a growing number of biomedical services out there on Wild Wild Web for performing various computations on DNA, RNA and proteins as well as the associated scientific literature. Currently, using and debugging these services can be hard work. SOAP UI (SOAP User Interface) is newish and handy free tool to help debug services and get your in silico experiments and analyses done, hopefully more easily.
So why should bioinformaticans care about Web Services? Three of the most important advantages are:
- They can reduce the need to install and maintain hundreds of tools and databases locally on desktop(s) or laboratory server(s) as these resources are programmatically accessible over the web.
- They can remove the need for tedious and error-prone screen-scraping, or worse, “cut-and-paste” of data between web applications that don’t have fully programmatic interfaces.
- It is possible to compose and orchestrate services into workflows or pipelines, which are repeatable and verifiable descriptions of your experiments that you can share. Needless to say, sharing repeatable experiments has always been important part of science, its shouldn’t be any different on the Web of Science.
All this distributed computing goodness comes at a price though and there are several disadvantages of using web services. We will focus on one here: Debugging services, which can be problematic. In order to do this, bioinformaticians need to understand a little bit about how web services work and how to debug them.
Death by specification
Debugging services sounds straightforward, but many publicly available biomedical services, are not the simpler RESTian type, but the more complex SOAP-and-WSDL type of web service. Consequently, debugging usually requires a basic understanding these protocols and interfaces, the so-called “Simple” Object Access Protocol (SOAP) and Web Services Description Language (WSDL). However these specifications are both big, complicated and being superceded by newer versions so you might lose the will-to-live while reading them. Also, individual services described in WSDL are easier for machines to read, than for humans, and therefore give humble bioinformaticians a big headache. As an example, have a look at the WSDL for BLAST at the DNA Databank of Japan (DDBJ).
So, if you’re not intimately familiar with the WSDL 1.1 specification (frankly, life is too short and they keep moving the goal-posts anyway), it is not very clear what is going on here. WSDL describes messages, port types, end points, part-names, bindings, bla-bla-bla, and lots of other seemingly unnecessary abstractions. To add insult to injury WSDL is used in several different styles and is expressed in verbose XML. Down with the unnecessary abstractions! But the problems don’t stop there. From looking at this WSDL, you have to make several leaps of imagination to understand what the corresponding SOAP messages this BLAST service accepts and responds with will look like. So when you are analysing your favourite protein sequence(s) with BLAST or perhaps InterProScan it can be difficult or impossible to work out what went wrong.
Using SOAPUI
This is where SOAPUI, can make life easier. You can launch SOAPUI using the Java Web Start, load a WSDL in and you can begin to see what is going on. One of the nice features, is it will show you what the SOAP messages look like, which saves you having to work it out in your head. So, going back to our BLAST example…
- Launch the SOAPUI tool and select File then New WSDL Project (Give project a name and save it when prompted).
- Right click on the Project folder and select add WSDL from URL
- Type in http://xml.nig.ac.jp/wsdl/Blast.wsdl or your own favourite from this list of molecular biology wsdl.
- When asked: Create default requests for all operations select Yes
- The progress bar will whizz away while it imports the file, once its done, you can see a list of operations
- If you click on one of them e.g. searchParam then Request1, then select Open Request Editor it spawns two new windows…
- The first (left-hand) window shows the SOAP request that is sent to the BLAST service:
<soapenv:Envelope ... boring namespace declarations ... > <soapenv:Body> <blas:searchParam soapenv:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"> <!-- use BLASTp --> <program xsi:type="xsd:string">blastp</program> <!-- Use SWISSPROT data --> <database xsi:type="xsd:string">SWISS</database> <!-- protein sequence --> <query xsi:type="xsd:string">MHLEGRDGRR YPGAPAVELL QTSVPSGLAE LVAGKRRLPR GAGGADPSHS</query> <!-- no parameters --> <param xsi:type="xsd:string"></param> </blas:searchParam> </soapenv:Body> </soapenv:Envelope>
- When you click on the green request button, this message is sent to the service. Note: you have to fill in the parameters values as they default to: “?”.
- After submitting the request above, the SOAP response appears in the second (right-hand) window:
<soap:Envelope ... namespace declarations... > <soap:Body> <n:searchParamResponse xmlns:n="http://tempuri.org/Blast"> <Result xsi:type="xsd:string">BLASTP 2.2.12 [Aug-07-2005] ... Sequences producing significant alignments: (bits) Value sp|Q04671|P_HUMAN P protein (Melanocyte-specific transporter pro... 104 8e-23 ... </Result> </n:searchParamResponse> </soap:Body> </soap:Envelope>
Not all users of web services will want the gory details of SOAP, but for serious users, its a handy tool for understanding how any given web service works. This can be invaluable in working out what happened if, or more probably when, an individual service behaves unexpectedly. If you know of any other tools that make web services easier to use and debug, I’d be interested to hear about them.
Conclusions: It’s not rocket science
In my experience, small tools (like SOAPUI) can make a BIG difference. I’ve used a deliberately simple (and relatively reliable) BLAST service for demonstration purposes, but the interested reader / hacker might want to use this tool to play with more complex programs like the NCBI Web Services or InterProScan at the EBI. Using such services often requires good testing and debugging support, for example, when you compose (or “mashup”) services into complex workflows, using a client such as the Taverna workbench. This is where SOAP UI might just help you test and debug web services provided by other laboratories and data centres around the world, so you can use them reliably in your in silico experiments.
Further reading
If you are interested in using Web Services to perform your own bioinformatics experiments, you may be interested in the following:
- A framework for deploying bioinformatics applications as high-throughput Web services on a BioGrid. IBM DeveloperWorks
- Integrate high-throughput services with Web services. IBM DeveloperWorks
- Deploying and consuming bioinformatics Web services. IBM DeveloperWorks
- Taverna: a tool for building and running workflows of services
- European Bioinformatics Institute (EBI) documentation on SOAPUI
- Automatic online data integration pipelines with Expression Profiler for bioinformatics programmers. Tutorial at ISMB 2006, Fortaleza, Brazil by Misha Kapushesky
- ACM Queue interview with Werner Vogels on the use of Web Services at Amazon.com
- This post was originally published on nodalpoint with comments

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 License.
May 24, 2006
Dub Dub Dub 2006

The 15th International World Wide Web conference is currently underway in Edinburgh, Bonny Scotland. As usual, this popular conference has some good papers, only 11%* of submissions are accepted. One particular paper caught my eye: One Document to Bind Them: Combining XML, Web Services, and the Semantic Web. This paper has probably been selected because it will wind people up (sorry I mean “spark a debate”) so its an entertaining and sometimes enlightening read.
In this paper, Harry Halpin and Henry Thompson make some observations about the state of the web in 2006:
- The Semantic Web stack and Web Service Stack, are a long long way from the web of everyday users, or to put it another way, there is too much theory and not enough practice.
- The web is in danger of becoming fragmented between XML, Web Services, Semantic Web, Second generation web, Asynchronous JavaScript and XML (AJAX) and microformats like Really Simple Syndication (RSS) etc
But, according to the authors, it doesn’t have to be this way…
- Many (but not all) web services are functions that are available on the web,
- The semantic web gives us an elaborate type system, using ontologies, which can extend what we already have with XML Schema
- The combination of the first two, gives us Semantic Web Services which are typed functions. This allows us to invoke web services not just by their URI (e.g. http://xml.nig.ac.jp/xddbj/Blast for a Blast service), but by the type of information they have. E.g. you have an output of type BLAST_report or perhaps InterProScan_report, what services will take this as input? What operations can be performed on this data? This sounds a lot like BioMOBY, with bells on.
What Harry and Henry propose is tying all this together using a single XML vocabulary, called Semantic fXML, to put “a unified abstraction of data, types and functions” so that the web can compute. This is all a bit pie-in-the-sky vision of the future stuff, but what might it mean for your average bioinformatican? It would be seriously useful if we could make the current molecular biology web services easier to use, but agreeing on and using an ontology for annotating the types of the inputs and outputs of all the services is non-trivial task. Bioinformaticians already have a (somewhat limited) universal type system for describing all data in bioinformatics, its called string. Persuading them to use something more powerful is not easy unless the benefits are immediately obvious.
At the moment, it is difficult to tell if sfXML will ever have any impact on bioinformatics but who cares? Despite this, the paper is enjoyable reminder of what is interesting about services on the Web. They transform the web from a place where we can merely search and browse for data (sequences, genes, proteins, metabolic pathways, systems etc), into “one vast de-centralised computer” a bit like the one described in can computers explain biology? This, in my humble opinion, is what makes the web and bioinformatics an exciting place to work in 2006.
* Footnote: Of nearly 700 papers submitted: only 81 research papers were accepted (11%). This is a 25% increase on the number of submissions last year to www2005 in Chiba, Japan.
References
- Harry Halpin and Henry S. Thompson (2006) One Document to Bind Them: Combining XML, Web Services, and the Semantic Web in Proceedings of the 15th international conference on World Wide Web, Edinburgh Scotland DOI:10.1145/1135777.1135877
- This post originally published on nodalpoint with comments

{kind=link}